

 Lic. Carlos Enrique Loria Beeche
Lic. Carlos Enrique Loria Beeche
Una prueba práctica con Windows 11, WSL 2, Docker y modelos locales para explorar inteligencia artificial sin entregar datos sensibles a terceros.
Hace poco recibí la llamada de un amigo, excompañero de colegio, que colabora con una empresa. Me hizo una pregunta muy concreta: ¿se puede utilizar inteligencia artificial localmente, sin depender siempre de plataformas externas?
Mi respuesta profesional fue inmediata: definitivamente sí.
Pero la pregunta no era simplemente técnica. No se trataba solo de instalar un programa, descargar un modelo o seguir una moda. Detrás de esa inquietud hay una preocupación mucho más seria: ¿qué pasa con la información sensible de una empresa cuando empezamos a usar inteligencia artificial?
Desde hace años mi posición profesional ha sido bastante clara: hay que tener mucho cuidado antes de entregar información sensible a terceros. No por miedo a la tecnología. Al contrario, precisamente porque he trabajado durante años con sistemas, bases de datos, automatización, servidores propios, modelos locales y herramientas de análisis, sé que no toda información debe salir alegremente de la organización.
Un análisis de cuentas por cobrar, por ejemplo, puede requerir datos detallados de clientes, ventas, facturas, antigüedad de saldos, pagos pendientes, comportamiento histórico, condiciones comerciales y decisiones internas. Esa información no es cualquier cosa. Es parte del corazón operativo y financiero de una empresa.
Hoy hablamos mucho de “la nube”, y la palabra a veces suena casi mágica. Pero conviene recordar algo muy simple: una computadora en la nube sigue siendo una computadora, solo que está en la infraestructura de alguien más.
Eso no significa que toda nube sea insegura, ni que todos los proveedores actúen mal. Existen contratos, auditorías, certificaciones, acuerdos de confidencialidad, políticas de acceso y controles técnicos. Pero aun así, desde el punto de vista profesional, el dato ya salió del perímetro directo de la empresa.
Y cuando el dato sale, cambia el tipo de riesgo.
La nube no elimina el problema de confianza; lo traslada a otro custodio.
Por eso la pregunta de mi amigo me pareció tan oportuna. No era una pregunta teórica. Era una pregunta muy práctica: ¿puede una empresa empezar a explorar inteligencia artificial local usando equipo relativamente común, manteniendo sus datos bajo mayor control?
Windows no puede quedar fuera de la conversación
Muchos laboratorios de inteligencia artificial local se documentan sobre Linux. Eso tiene mucho sentido: Linux domina muchos entornos de servidor, desarrollo, automatización, contenedores y administración técnica. Muchas herramientas nacieron allí y corren con mucha naturalidad en ese mundo.
Pero la realidad diaria de muchas empresas es otra.
Muchos usamos Windows todos los días. Y en muchísimas empresas, especialmente en áreas administrativas, contables, comerciales, gerenciales y operativas, Windows sigue siendo el ambiente normal de trabajo.
Conviene aclarar algo: esto no significa que Windows sea el único camino. En muchas gerencias, áreas creativas, consultorías y equipos directivos también encontramos computadoras Mac. Y las Mac modernas con Apple Silicon —especialmente las que usan chips M1, M2, M3 o M4— se han vuelto muy interesantes para inteligencia artificial local.
Una de sus ventajas es la memoria unificada. Dicho en sencillo: en muchos de estos equipos, el procesador, la parte gráfica y otros componentes especializados pueden trabajar sobre un mismo espacio de memoria. Eso no hace milagros, pero sí puede ayudar cuando se ejecutan modelos de IA local, porque estos modelos necesitan cargar bastante información en memoria para funcionar bien. En Mac también se pueden usar herramientas como LM Studio, Ollama o Docker Desktop.
Ahí están Excel, los reportes, los sistemas contables, las carpetas compartidas, el correo, las conexiones remotas, los programas administrativos y buena parte del trabajo cotidiano de los usuarios.
Por eso, si queremos hablar de inteligencia artificial local al alcance de la mano, Windows tiene que estar en la conversación.
Las estadísticas globales de escritorio ayudan a entender ese punto. Según StatCounter, en mayo de 2026 Windows mantenía la mayor participación mundial en sistemas operativos de escritorio, con 62.16%. Si se suman OS X y macOS, el ecosistema de escritorio de Apple rondaba el 14.58%, mientras Linux aparecía con 3.09% y Chrome OS con 1.42%. Dentro del propio ecosistema Windows, Windows 11 ya era la versión dominante, con 71.69% frente a 26.36% de Windows 10.
Estas cifras no son una medición específica del mercado corporativo costarricense, pero sí refuerzan una idea práctica: si queremos que la inteligencia artificial local sea realmente accesible para empresas y usuarios cotidianos, no basta con pensar en servidores Linux. También hay que pensar en la computadora Windows que ya está sobre el escritorio.
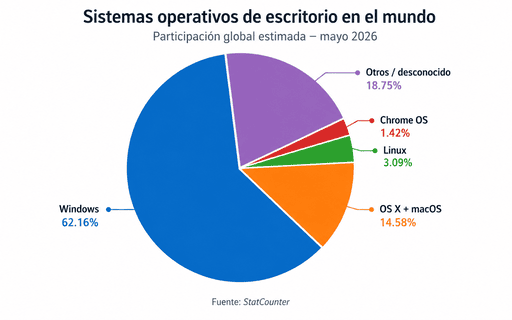
Fuente: StatCounter Global Stats, Desktop Operating System Market Share Worldwide, mayo 2026.
https://gs.statcounter.com/os-market-share/desktop/worldwide/
Antes de instalar nada: memoria, modelo y expectativas
Antes de entrar en herramientas concretas como WSL, Docker, Ollama, LM Studio o Docker Model Runner, conviene hacer una aclaración sencilla.
Mientras preparaba este artículo vi un video de un creador tecnológico que explicaba muy bien una idea clave: para correr inteligencia artificial local, la memoria RAM —o la memoria de la tarjeta gráfica, conocida como VRAM— es determinante.
A veces pensamos primero en el procesador, en la marca de la computadora o en la tarjeta gráfica. Pero en IA local hay una pregunta todavía más básica: ¿el modelo cabe en memoria?
Una analogía útil es pensar en una cocina. El procesador o la tarjeta gráfica serían como el chef, pero la memoria es la mesa de trabajo. Si la mesa es pequeña, el chef puede ser muy bueno, pero no tendrá espacio suficiente para trabajar con comodidad. Tendrá que estar guardando y sacando cosas constantemente, y todo se volverá más lento.
Con los modelos de IA ocurre algo parecido. El modelo puede estar guardado en el disco duro, pero cuando se ejecuta necesita cargarse en memoria. Además, la conversación también ocupa memoria: mientras más larga sea, más contexto debe mantener el sistema.
Por eso una computadora común puede servir para empezar, pero no todos los modelos funcionarán igual de bien. Un modelo pequeño puede responder de forma aceptable. Un modelo más grande puede razonar mejor, pero también necesitará más memoria y más capacidad de cómputo.
En mi prueba, con una PC Windows 11, 32 GB de RAM y sin GPU dedicada para IA, fue posible ejecutar Qwen2.5 7B cuantizado. Funcionó, respondió por consola y también por API local. Pero la velocidad fue limitada: alrededor de 4.7 tokens por segundo.
Dicho de forma sencilla: la prueba confirmó que se puede. Pero también confirmó que la experiencia depende mucho del tamaño del modelo, de la memoria disponible y del hardware.
Para empezar no hace falta una supercomputadora. Pero sí hace falta entender los límites del equipo que tenemos.
Con esa idea clara —que no basta con descargar un modelo, sino que hay que tener memoria suficiente para usarlo bien— ya podemos entrar en las herramientas. Pero antes, vale la pena traducir algunos términos para que el resto del artículo no parezca escrito en ruso.
Un pequeño diccionario para no escribir en ruso
Antes de seguir, conviene hacer una pausa.
Como científico en computación y profesor universitario retirado, reconozco que puedo tener cierto sesgo hacia lo técnico. Durante muchos años mi mundo ha estado lleno de sistemas, bases de datos, servidores, lenguajes de programación, redes, bits y bytes.
Pero algo que he aprendido, tal vez ya entrado en años, es que hay muchas formas de inteligencia.
Una persona puede ser brillante en finanzas, ventas, administración, medicina, derecho, psicología, educación o tecnología, sin tener que saber configurar un servidor o entender una consola de comandos.
Así que, para que mi hermana y mi tía no digan que estoy escribiendo en ruso o en algún idioma extranjero, vale la pena hacer una pequeña traducción de algunos términos.
No se trata de memorizar tecnicismos. Se trata de entender qué problema resuelve cada cosa y para qué puede servir en la vida real.
WSL 2: permite usar Linux dentro de Windows. Es como abrir una puerta técnica dentro de la computadora Windows para usar herramientas que tradicionalmente funcionaban mejor en Linux.
Linux: sistema operativo muy usado en servidores, laboratorios técnicos, desarrollo de software y automatización.
Docker: permite ejecutar servicios en “contenedores”, como si fueran cajas separadas y ordenadas. Eso ayuda a instalar, probar, apagar o eliminar herramientas sin desordenar toda la computadora.
Docker Model Runner: herramienta de Docker para ejecutar modelos de inteligencia artificial localmente y permitir que otras aplicaciones los usen.
Ollama: herramienta muy popular para descargar y correr modelos de IA en la propia computadora.
LM Studio: aplicación visual de escritorio para buscar, descargar y probar modelos de IA locales sin empezar escribiendo comandos. Es desarrollada por Element Labs Inc.
Modelo local: un modelo de inteligencia artificial que corre en la propia computadora o servidor de la empresa, no necesariamente en la nube.
API: una forma ordenada para que un programa hable con otro programa. En este caso, permite que una aplicación interna le haga preguntas a un modelo de IA.
RAG: técnica que permite que la IA consulte documentos o datos propios antes de responder. Por ejemplo, manuales internos, políticas, reportes o bases documentales.
n8n: herramienta para automatizar procesos. Sirve para conectar pasos, sistemas y acciones, como leer datos, enviar mensajes, consultar una base de datos o activar una tarea.
CORS: regla de seguridad que controla desde qué sitios web se puede llamar a un servicio. Dicho sencillo: ayuda a evitar que cualquier página web externa se conecte alegremente a un servicio local o interno.
localhost: significa “esta misma computadora”. Cuando un servicio queda en localhost, en principio solo se usa desde la propia máquina, no desde toda la red.
Puerto: una puerta de entrada técnica a un servicio. Por ejemplo, un programa puede quedar escuchando en el puerto 12434. Si esa puerta queda abierta sin control, puede convertirse en un riesgo.
Estos nombres pueden sonar complicados, pero la idea de fondo es sencilla: usar inteligencia artificial de forma más controlada, más cercana a los datos de la empresa y con menos dependencia de enviar información sensible a terceros.
WSL 2: Linux dentro de Windows
Aquí entra una pieza muy importante: WSL 2, el Subsistema de Windows para Linux.
Microsoft ha hecho un esfuerzo importante por acercar lo mejor del mundo Linux al entorno Windows. Con WSL 2 es posible instalar una distribución Linux, como Ubuntu, dentro de Windows, ejecutar comandos Linux, usar herramientas modernas de desarrollo y trabajar con servicios técnicos sin abandonar el ambiente principal del usuario.
Eso cambia el panorama.
Ya no es obligatorio escoger entre “uso Windows” o “uso Linux”. Para muchos escenarios prácticos, se puede usar Windows como sistema principal y Linux como capa técnica integrada.
En esta prueba instalé Ubuntu 26.04 dentro de Windows 11 mediante WSL 2. Eso permitió trabajar con herramientas Linux, consola, Docker, contenedores y servicios locales, pero sin dejar de usar Windows como sistema principal.
Para una empresa, ese detalle es muy importante. No siempre se puede pedir que todo el mundo cambie a Linux. Pero sí se puede aprovechar Linux dentro de Windows para abrir la puerta a laboratorios modernos de inteligencia artificial, automatización y análisis de datos.
La IA local estará realmente al alcance de la mano cuando pueda funcionar también en la computadora que la gente ya usa todos los días.
Docker como primera opción natural
Por mi experiencia previa con laboratorios de IA local, Docker apareció como una primera opción natural.
Ya había trabajado antes con stacks basados en contenedores: Ollama, Open WebUI, n8n, Qdrant, PostgreSQL, WAHA, Flowise y otros servicios. Docker permite activar, apagar, probar, eliminar y reconstruir componentes de forma ordenada. Para un laboratorio técnico, eso es una gran ventaja.
En artículos anteriores ya había documentado experiencias con stacks locales de inteligencia artificial basados en Docker, incluyendo ambientes más completos y orientados a servidor. Pero esta vez el enfoque era diferente.
La pregunta no era cómo montar una plataforma completa en Linux.
La pregunta era más cercana: ¿qué se puede hacer desde una PC Windows común?
Por eso empecé instalando Docker Desktop sobre Windows 11, integrado con Ubuntu mediante WSL 2.
La primera prueba fue sencilla: confirmar que Docker funcionaba. Primero con el clásico hello-world, luego con un contenedor Nginx publicado en localhost:8080. Cuando Nginx respondió desde el navegador de Windows, quedó claro que la base estaba lista: Windows, WSL 2, Ubuntu y Docker podían trabajar juntos.
A partir de ahí activé Docker Model Runner, una opción más reciente dentro del ecosistema Docker que permite descargar y ejecutar modelos locales, exponerlos por API y conectarlos eventualmente con aplicaciones internas.
No empecé por Docker porque sea la única alternativa. Empecé por Docker porque, para un laboratorio técnico y modular, era el camino más coherente con lo que ya venía trabajando.
Docker Model Runner y la primera prueba con modelos locales
Docker Model Runner permite gestionar y ejecutar modelos de inteligencia artificial desde el propio ecosistema Docker. Su atractivo no está en ser la interfaz más bonita para conversar con un modelo, sino en integrarse con herramientas de desarrollo, APIs locales y flujos donde una aplicación pueda consumir un modelo como servicio.
En la prueba, primero se verificó que Docker Model Runner estuviera activo.
Luego se consultó el endpoint local en:
http://localhost:12434/engines/v1/models
Al inicio la lista apareció vacía, como era de esperar. Todavía no había modelos descargados.
La primera descarga fue un modelo pequeño, smollm2, útil para comprobar infraestructura. Ese modelo sirvió para validar que el mecanismo funcionaba: Docker podía descargar el modelo, registrarlo y ejecutarlo localmente.
Después vino una prueba más seria con Qwen:
qwen2.5:7B-Q4_K_M
Qwen es una familia de modelos de la que se habla mucho en el mundo de IA local. Tiene variantes pequeñas, medianas y grandes, y se ha vuelto popular en pruebas relacionadas con texto, código, razonamiento y uso multilingüe.
En este caso no se trataba de competir contra los grandes modelos en la nube. Se trataba de hacer una prueba razonable con una computadora común: Windows 11, 32 GB de RAM y sin GPU dedicada para acelerar el modelo.
El resultado fue honesto: funcionó.
El modelo respondió por consola y también mediante API local. Pero en CPU, sin GPU dedicada, la respuesta fue lenta. Además, con un prompt muy general, la calidad de la respuesta fue también bastante general.
Eso no invalida la prueba. Al contrario, la hace más creíble.
Una PC común puede ejecutar un modelo local, pero hay que entender sus límites. No se puede esperar que responda con la velocidad de una infraestructura especializada. Tampoco se puede esperar que un prompt vago produzca automáticamente una respuesta excelente.
La IA local requiere tres cosas: buen criterio técnico, buenos prompts y expectativas realistas.
LM Studio, Ollama y Docker Model Runner
Aunque en esta prueba empecé por Docker Model Runner, no creo que exista una única forma correcta de usar inteligencia artificial local.
Hay varias puertas de entrada.
Ollama es probablemente una de las opciones más conocidas entre usuarios técnicos. En mi caso, además, ya lo venía usando desde hace tiempo, por lo que me resulta familiar. Su fortaleza está en la simplicidad: descargar un modelo, ejecutarlo y empezar a conversar suele ser bastante directo.
LM Studio es probablemente la entrada más amigable para quien quiere probar IA local sin empezar por consola. Permite buscar modelos, descargarlos y conversar con ellos desde una aplicación visual de escritorio. Para usuarios más avanzados, también puede levantar un servidor local para que otras aplicaciones consuman el modelo mediante API.
Docker Model Runner, en cambio, resulta especialmente interesante cuando uno piensa en integración técnica, APIs locales, Docker Desktop, automatización y desarrollo de aplicaciones internas.
Dicho de forma simple:
- LM Studio puede ser más cómodo para probar modelos visualmente.
- Ollama es muy popular, práctico y conocido por muchos usuarios técnicos.
- Docker Model Runner es atractivo para integración, desarrollo y servicios locales.
La elección final no necesariamente debe hacerse de forma dogmática. Puede depender del departamento de TI, del consultor responsable, del nivel técnico del equipo y de las necesidades concretas de la empresa.
Lo importante es que las opciones existen. Y hoy pueden probarse en una computadora común.
Más que modelos: automatización
Tener Docker instalado también abre otra puerta: la automatización.
No se trata solo de ejecutar un modelo local. Con Docker se pueden levantar herramientas como n8n, bases de datos, motores vectoriales para RAG, interfaces web y pequeños servicios internos.
Eso permite construir flujos donde la inteligencia artificial no trabaja sola, sino conectada con datos, reglas, procesos y aplicaciones.
Por ejemplo, una empresa podría pensar en una arquitectura local sencilla:
- un modelo local para análisis o generación de texto;
- n8n para coordinar flujos de trabajo;
- una base de datos para guardar información;
- un motor vectorial para búsquedas semánticas sobre documentos internos;
- una interfaz web para consultar resultados;
- y eventualmente una aplicación interna conectada por API.
Ahí Docker tiene una ventaja práctica: permite probar estas piezas por separado, activarlas, apagarlas, reemplazarlas o eliminarlas sin convertir la computadora principal en un desorden de instalaciones difíciles de mantener.
En el contexto empresarial, esto abre una posibilidad interesante. La IA local no tiene por qué ser una aplicación aislada. Puede convertirse en parte de un flujo automatizado: leer información, clasificarla, resumirla, cruzarla con datos internos, generar alertas, preparar reportes o alimentar una hoja de análisis.
Ahí es donde Docker deja de ser solo una herramienta técnica y se convierte en una base práctica para experimentar con soluciones internas.
Local no significa automáticamente seguro
Ahora bien, hay una advertencia importante.
Instalar un modelo local no garantiza, por sí solo, que la información esté protegida.
Uno de los errores más comunes en estos laboratorios es dejar un servicio escuchando más allá de lo necesario. A veces el usuario cree que está trabajando “localmente”, pero en realidad dejó abierto un puerto accesible desde otros equipos de la red, o incluso desde fuera, sin darse cuenta.
Eso puede traer varios riesgos:
- que otra persona consuma el modelo sin autorización;
- que un tercero use la máquina como recurso de cómputo;
- que una aplicación mal configurada consulte información sensible;
- o, en el peor caso, que datos internos queden expuestos por una mala configuración.
Por eso, en esta prueba tomé una decisión deliberada: Docker Model Runner quedó enlazado únicamente a localhost.
En otras palabras, el servicio quedó disponible solo dentro de la misma computadora. No quedó escuchando en todas las interfaces de red, ni abierto a otros equipos del segmento local.
También evité habilitar CORS amplios o configuraciones permisivas innecesarias. Para un laboratorio inicial, la mejor práctica no es abrir primero y proteger después, sino exactamente al revés: cerrar por defecto y abrir solo lo estrictamente necesario.
Esto vale no solo para Docker Model Runner, sino para cualquier motor local de IA, incluyendo Ollama, LM Studio, Open WebUI, n8n, bases de datos, motores vectoriales o cualquier otro servicio auxiliar.
Local no siempre significa seguro. Local bien configurado, sí.
La soberanía de los datos también exige disciplina técnica.
Una PC común no reemplaza un centro de datos
Conviene ser claros.
Una computadora común no va a competir con un centro de datos especializado. Tampoco va a responder igual que los grandes modelos comerciales que corren sobre infraestructuras enormes, con GPUs de alto rendimiento, memoria abundante, optimizaciones avanzadas y costos de operación importantes.
Pero esa no era la pregunta.
La pregunta no era si una PC de escritorio puede ganarle a una infraestructura de cientos de miles de dólares.
La pregunta era si una empresa, un consultor o un departamento de TI puede empezar a explorar inteligencia artificial local desde equipo razonable, sin entregar de inmediato datos sensibles a terceros.
Y ahí la respuesta es sí.
Con limitaciones, sí.
Con cuidado, sí.
Con disciplina técnica, sí.
Pero sí.
No es una solución única, es un camino gradual
La IA local no debe verse como una sola herramienta ni como una sola arquitectura.
Puede empezar de forma pequeña: una PC Windows, WSL 2, Docker Desktop y un modelo local.
Luego puede crecer hacia otros componentes: Ollama, LM Studio, Open WebUI, n8n, Qdrant, PostgreSQL, RAG, APIs internas o servidores Linux dedicados.
Cada empresa tendrá que decidir hasta dónde quiere llegar. Algunas solo necesitarán experimentar. Otras querrán automatizar procesos. Otras necesitarán integrar datos internos, documentos, reportes, análisis financieros o flujos operativos.
Lo importante es entender que ya no estamos hablando de ciencia ficción ni de una tecnología reservada únicamente para grandes corporaciones.
Hoy una computadora común puede ser el primer escalón.
Conclusión
La llamada de mi amigo sirvió para poner sobre la mesa una inquietud muy actual: cómo aprovechar inteligencia artificial sin perder innecesariamente el control sobre los datos.
La respuesta no es abandonar la nube, ni rechazar las plataformas externas, ni creer que todo debe hacerse localmente. La respuesta es más equilibrada: entender qué tipo de información estamos usando, qué riesgos estamos aceptando y qué alternativas tenemos.
Para muchas tareas, la nube seguirá siendo útil. Para otras, especialmente cuando hay datos sensibles, la IA local puede ser una opción muy valiosa.
Y lo más interesante es que ya no está tan lejos.
Con Windows 11, WSL 2, Docker Desktop y herramientas como Docker Model Runner, Ollama o LM Studio, la inteligencia artificial local empieza a estar verdaderamente al alcance de la mano.
Apéndice técnico: para colegas y departamentos de TI
Hasta aquí he tratado de mantener el artículo en un lenguaje accesible para cualquier persona interesada en el tema, aunque no sea técnica.
Pero como sé que entre los lectores también hay colegas que hacen magia con servidores, redes, contenedores, bases de datos y automatizaciones, dejo a continuación una sección más técnica.
A partir de aquí, con cariño y respeto, ya no estamos en terreno para muggles tecnológicos. Aquí entran comandos, puertos, endpoints, modelos, WSL, Docker, seguridad y algunas decisiones prácticas que conviene documentar si alguien quiere reproducir la prueba o llevarla a un entorno empresarial.
Equipo base de la prueba
La prueba se realizó sobre una computadora Windows 11 de uso cotidiano, con 32 GB de RAM y sin GPU dedicada para acelerar modelos de IA.
La intención no fue construir una estación especializada, sino validar si una PC común podía servir como punto de entrada para IA local.
WSL 2 y Ubuntu
Primero se instaló Ubuntu dentro de Windows mediante WSL 2.
Comando base:
wsl --install -d Ubuntu-26.04
Luego se verificó que Ubuntu estuviera corriendo en WSL 2:
wsl -l -v
La instalación quedó con Ubuntu 26.04 en versión WSL 2.
Docker Desktop e integración con WSL
Después se instaló Docker Desktop y se activó la integración con Ubuntu desde:
Settings → Resources → WSL Integration
Se verificó Docker con:
docker version
docker run hello-world
docker compose version
También se probó un contenedor Nginx:
docker run --name prueba-nginx -d -p 8080:80 nginx:alpine
Y se verificó desde el navegador:
http://localhost:8080
Luego se limpió la prueba:
docker stop prueba-nginx
docker rm prueba-nginx
Docker Model Runner
Se activó Docker Model Runner desde Docker Desktop.
La configuración inicial fue conservadora:
TCP Port: 12434
Bind address: localhost / 127.0.0.1
CORS allowed origins: none
Se verificó la versión:
docker model version
Y se consultó el endpoint local:
curl.exe http://localhost:12434/engines/v1/models
Inicialmente la lista de modelos apareció vacía.
Modelos probados
Primero se descargó un modelo pequeño para validar infraestructura:
docker model pull ai/smollm2
Luego se descargó Qwen2.5 7B cuantizado:
docker model pull ai/qwen2.5:7B-Q4_K_M
Se pudo ejecutar el modelo desde consola y también consumirlo por API local.
API local
El endpoint utilizado fue:
http://localhost:12434/engines/v1/chat/completions
La prueba por API confirmó que una aplicación local podría consumir el modelo como servicio, sin salir a internet para cada consulta.
Rendimiento observado
En la prueba con Qwen2.5 7B cuantizado, ejecutado en CPU, se obtuvo una velocidad aproximada de 4.7 tokens por segundo.
Eso es suficiente para confirmar funcionamiento, pero no para una experiencia fluida comparable a servicios cloud o a equipos con GPU dedicada.
La conclusión técnica es clara:
- la arquitectura funciona;
- la integración local es viable;
- la experiencia mejora mucho con mejor hardware;
- la memoria RAM o VRAM disponible es un factor crítico;
- y los modelos deben escogerse según el equipo real, no según entusiasmo.
Seguridad práctica
La decisión más importante fue no exponer el servicio fuera de la máquina.
Para laboratorio inicial:
localhost / 127.0.0.1: sí
0.0.0.0: no
CORS abierto: no
puertos publicados a la red: no
Si en una fase posterior se decide exponer el servicio a otros equipos, convendría hacerlo mediante reglas claras:
- firewall;
- autenticación;
- red privada;
- VPN;
- reverse proxy controlado;
- segmentación de red;
- monitoreo de uso;
- y revisión cuidadosa de qué datos puede consultar el modelo.
Próximos pasos posibles
Esta prueba puede crecer en varias direcciones:
- comparar Docker Model Runner con Ollama y LM Studio;
- levantar Open WebUI como interfaz;
- conectar n8n para automatización;
- incorporar Qdrant o una base vectorial;
- construir un RAG con documentos internos;
- conectar una aplicación empresarial mediante API;
- o mover la carga a una estación Linux con GPU dedicada.
El punto de partida, sin embargo, ya quedó demostrado: una PC Windows común puede abrir la puerta a la IA local.
Artículos relacionados
Para quien quiera profundizar en la línea de trabajo que he venido documentando, estos artículos anteriores pueden servir como referencia:
- Cloria AI Stack: cómo montar tu propio “cerebro” de IA con Docker en Ubuntu y en macOS.
- Actualizando un stack de IA local en producción: Open WebUI, n8n, Ollama y más paso a paso.
- Arquitectura que produce inteligencia: decisiones nacidas del flujo
Aquellos artículos están más orientados a stacks completos y ambientes de servidor. Este artículo tiene una intención más cercana: mostrar que una computadora Windows común también puede abrir la puerta a la inteligencia artificial local.