

 Lic. Carlos Enrique Loria Beeche.
Lic. Carlos Enrique Loria Beeche.
En diciembre de 2025 publiqué un artículo sobre cómo montar mi stack de IA local con Docker. Desde entonces, ese entorno dejó de ser una simple prueba de laboratorio: hoy funciona como una plataforma real de servicios interconectados, con interfaz de usuario, motor de modelos, automatización, base de datos vectorial para búsqueda semántica, persistencia relacional y exposición segura a Internet.
Este artículo es una actualización técnica de aquel primer post. Ya no se trata de montar el stack, sino de mantenerlo, actualizarlo y validarlo en producción sin romper servicios ni perder el control del entorno.
Post base relacionado:
Cloria AI Stack: cómo montar tu propio cerebro de IA con Docker en Ubuntu y en macOS
1. Contexto técnico
El host utilizado en esta fase de mantenimiento fue Pantera, un equipo con Ubuntu 22.04.5 LTS, Docker Engine 28.3.2 y Docker Compose v2.38.2. A nivel de CPU y memoria, el equipo tiene margen suficiente para mover un stack relativamente amplio; sin embargo, como suele ocurrir en producción, la verdadera limitación no siempre está en el procesador, sino en el almacenamiento disponible y en la disciplina operativa al momento de actualizar.
El objetivo fue actualizar los servicios activos de forma controlada, uno por uno, verificando el estado de cada contenedor antes de continuar con el siguiente.
2. Arquitectura actual del stack
Este es el conjunto principal de servicios activos durante esta fase:
- Ollama: runtime local para ejecutar modelos de lenguaje.
- Open WebUI: interfaz web para conversar con los modelos y administrar su uso.
- n8n: motor de automatización y orquestación de flujos.
- Qdrant: base de datos vectorial para embeddings y búsqueda semántica.
- WAHA: gateway HTTP para integración con WhatsApp.
- Cloudflared: túnel seguro para exponer servicios sin abrir puertos directos.
- Flowise: constructor visual de pipelines y agentes.
- supabase-api (PostgREST): capa REST automática sobre PostgreSQL.
- supabase-db: base PostgreSQL auxiliar para servicios REST.
- cloria-postgres: base de datos PostgreSQL principal del stack.
- xTeVe: componente auxiliar para flujos multimedia/IPTV.
- openbb-platform: imagen local personalizada, no actualizada en esta fase.
La siguiente imagen resume las principales consideraciones técnicas de esta actualización:
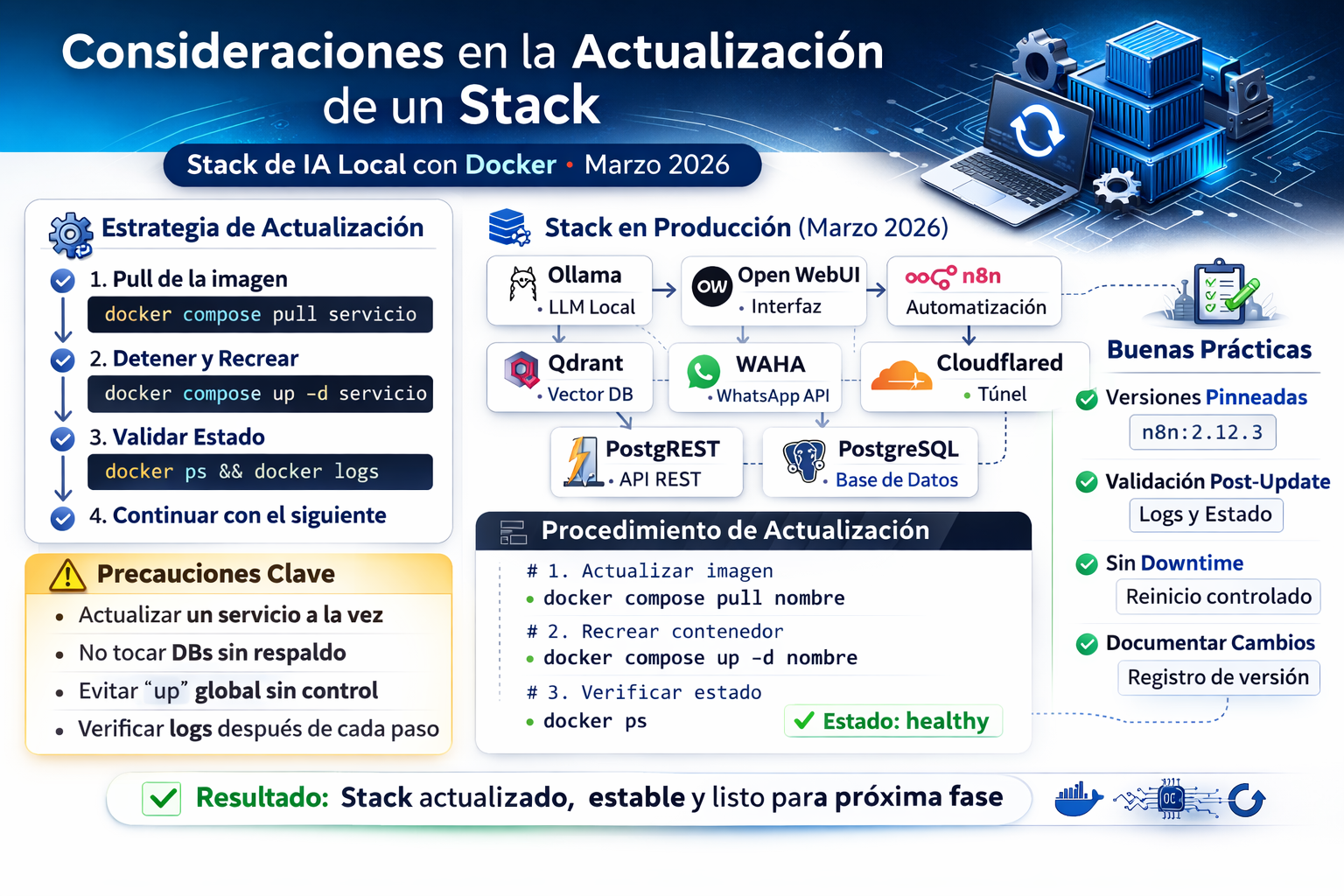
🧠 2.1 Mapa rápido del stack (qué hace cada componente)
Para quienes se acercan por primera vez a este tipo de arquitectura, este es un resumen funcional de cada pieza:
- Ollama: ejecuta modelos de lenguaje de forma local (LLMs).
- Open WebUI: interfaz web para interactuar con los modelos.
- n8n: motor de automatización que permite crear flujos (tipo Zapier, pero self-hosted).
- Qdrant: base de datos vectorial utilizada para almacenar embeddings y realizar búsqueda semántica.
- PostgreSQL: base de datos relacional para datos estructurados.
- WAHA: API para integrar WhatsApp dentro del ecosistema.
- Cloudflared: túnel seguro para exponer servicios sin abrir puertos directamente.
- Flowise: constructor visual de agentes y pipelines de IA.
Este tipo de arquitectura combina procesamiento local de IA, automatización y persistencia de datos en un entorno completamente controlado.
3. El principio clave: no actualizar todo a ciegas
Uno de los errores más comunes al trabajar con Docker Compose en un stack ya funcional es lanzar una actualización global sin discriminar servicios. En entornos pequeños tal vez eso no parezca grave, pero cuando el sistema ya tiene datos persistentes, integraciones activas y componentes personalizados, hacerlo así puede introducir errores difíciles de diagnosticar.
La estrategia aplicada aquí fue simple y eficaz:
- Descargar la nueva imagen de un servicio específico.
- Recrear únicamente ese contenedor.
- Verificar su estado, sus logs y su funcionamiento real.
- Solo entonces continuar con el siguiente servicio.
En otras palabras: actualización controlada por servicio, no por impulso.
4. Procedimiento general utilizado
El patrón de trabajo fue este:
docker compose pull SERVICIO
docker compose up -d SERVICIO
docker ps
docker logs --tail 30 SERVICIO
Este esquema permitió mantener el stack estable mientras se actualizaban gradualmente sus partes móviles.
La segunda imagen resume el inventario lógico del stack y las buenas prácticas aplicadas:

5. Servicios efectivamente actualizados
Durante esta sesión se actualizaron correctamente los siguientes componentes:
- Open WebUI
- Flowise
- n8n
- Qdrant
- Ollama
- WAHA
- Cloudflared
- supabase-api
- supabase-db
- xTeVe
El resultado fue satisfactorio: los contenedores fueron recreados sin pérdida visible de datos, sin caída general del stack y sin necesidad de una intervención destructiva.
6. Caso especial: actualización de n8n
Uno de los puntos más importantes fue n8n. Originalmente estaba fijado a la versión 1.120.0. Como no había flujos críticos de producción dependientes de esa versión antigua, se decidió aprovechar la oportunidad para migrar a una versión moderna y explícitamente fijada:
image: n8nio/n8n:2.12.3
Este cambio fue deliberado. En general, para componentes sensibles conviene evitar etiquetas ambiguas como latest o stable cuando se desea reproducibilidad. Una versión pinneada da más control y hace más fácil documentar el estado exacto del sistema.
7. Componentes que no se tocaron
No todo debe actualizarse en la misma sesión. En este caso hubo tres decisiones prudentes:
- cloria-postgres: no se tocó, por tratarse de una base de datos principal con datos relevantes.
- openbb-platform: no se tocó, porque está definido como imagen local personalizada (
openbb-platform:local) y no responde al mismo patrón de actualización por pull público. - Portainer: quedó fuera de esta ronda porque no forma parte del mismo proyecto Compose principal.
Este criterio es esencial: una actualización responsable no consiste en mover todo, sino en saber qué dejar quieto.
8. Validación posterior
Después de cada recreación se verificó el estado del contenedor correspondiente con comandos como estos:
docker ps --format 'table {{.Names}}\t{{.Status}}\t{{.Image}}'
docker logs --tail 30 open-webui
docker logs --tail 30 ollama
docker logs --tail 30 n8n
docker logs --tail 30 qdrant
docker logs --tail 30 cloria-postgres
Además de los comandos, se validó el funcionamiento real accediendo a las interfaces web de los servicios principales. Esto es importante: que un contenedor aparezca como Up no siempre basta; hay que confirmar que la aplicación siga respondiendo correctamente.
9. Lecciones prácticas
- Actualizar uno por uno reduce drásticamente el riesgo operativo.
- Los servicios con imagen local requieren un tratamiento distinto.
- Las bases de datos merecen un nivel superior de prudencia.
- Una advertencia visual en la interfaz no siempre justifica una actualización inmediata; primero hay que entender el contexto.
- Documentar lo que se hizo convierte una sesión tensa de mantenimiento en una referencia útil para el futuro.
10. Estado resultante
Al finalizar, el stack quedó actualizado, consistente y listo para la siguiente fase de trabajo. En particular:
- Open WebUI quedó funcional y saludable.
- n8n quedó actualizado a la versión 2.12.3.
- Ollama siguió respondiendo correctamente como backend local de modelos.
- Qdrant, WAHA, Flowise y Cloudflared continuaron operativos.
- No hubo evidencia de pérdida de volúmenes ni de corrupción visible de datos.
11. Conclusión
Montar un stack de IA local es solo el inicio. Lo que verdaderamente distingue a un entorno productivo de un experimento doméstico es la forma en que se opera, se mantiene y se actualiza.
En esta sesión, el valor no estuvo solo en descargar imágenes nuevas, sino en aplicar un método: observar, aislar, recrear, validar y documentar. Ese método es el que permite que un stack crezca sin convertirse en una fuente permanente de ansiedad.
La próxima etapa natural ya no es la infraestructura básica, sino la construcción de flujos inteligentes encima de ella: por ejemplo, integrar WAHA + n8n + Ollama + Qdrant para orquestar automatización, memoria y conversación local.
12. Referencia al artículo anterior
Si quieres ver el punto de partida de este proyecto, aquí está el artículo base:
Cloria AI Stack: cómo montar tu propio cerebro de IA con Docker en Ubuntu y en macOS