

 Lic. Carlos Enrique Loria Beeche.
Lic. Carlos Enrique Loria Beeche.
Fuente histórica de mi biblioteca de controles
Esta entrada es un complemento técnico del artículo Raíces fonéticas: cuando un nombre encuentra a la persona correcta.
En aquel artículo expliqué cómo una búsqueda fonética inspirada en técnicas como Soundex podía ayudar a encontrar personas aunque sus nombres estuvieran escritos de forma distinta. Aquí quiero bajar un nivel más y mirar la anatomía de una clase concreta: una clase que formó parte de mi biblioteca de controles y que ayudaba a convertir nombres escritos por personas en códigos fonéticos útiles para buscar coincidencias.
La clase se llama Fonetica. Probablemente nació originalmente en C++, hacia finales de los años ochenta o principios de los noventa, cuando trabajaba en sistemas de reservaciones y recepción hotelera. Más adelante, con la llegada de C# y el ecosistema .NET, la convertí a una clase reutilizable dentro de mi software.
No era una implementación pura de Soundex. Era una solución propia, criolla, inspirada en búsquedas fonéticas y adaptada a problemas reales: nombres escritos de distintas maneras, tildes omitidas, apellidos incompletos, errores de digitación y variaciones de pronunciación.
El nombre seguía siendo humano; el código fonético era una pista para que el sistema pudiera buscar mejor.
Investigar también depende de las herramientas y de las personas
Antes de entrar en la anatomía de la clase, quiero dejar claro algo: esta solución no nació de la nada. Nació de años de trabajo, de curiosidad técnica, de investigación y también de la ayuda de personas que, en momentos importantes, me mostraron caminos nuevos.
En aquellos años, investigar un tema técnico no era como hoy. La búsqueda tradicional significaba ir a una biblioteca, conocer autores, buscar títulos, revisar índices, conseguir manuales o esperar revistas técnicas. El conocimiento llegaba, pero muchas veces llegaba con rezago.
Por eso quiero agradecer a Miguel Fonseca Borrasé. Miguel fue una de las personas que me ayudó a descubrir herramientas que, para la época, eran verdaderas ventanas al mundo. Me enseñó a usar Gopher y Archie, herramientas que permitían explorar servidores, recorrer directorios, localizar archivos y encontrar información técnica distribuida en universidades y centros de cómputo.
Gracias a ese tipo de búsquedas era posible investigar temas como Soundex, algoritmos, protocolos, sockets y técnicas de programación. No era tan inmediato como abrir un buscador moderno, pero para quienes estábamos aprendiendo y construyendo software, era una puerta inmensa.
Recuerdo que usaba esas herramientas para investigar en un servidor de la Escuela de Ciencias de la Computación e Informática de la Universidad de Costa Rica llamado Chacal. En aquellos tiempos parecía casi obligatorio que todo centro de cómputo tuviera un servidor llamado Wolf; pero en la ECCI, con carácter propio, teníamos Chacal.
Más adelante, también con Miguel, vi por primera vez herramientas como Mosaic y Netscape, cuando apenas empezaba a tomar forma visible la World Wide Web.
Uno no aprende solo. Siempre hay alguien que enseña una herramienta, abre una puerta o deja una curiosidad sembrada.
Por eso esta clase Fonetica no representa solamente una pieza de código. También representa una época: una forma de investigar, de buscar conocimiento, de experimentar y de convertir ideas encontradas en soluciones útiles para problemas reales.
Fuente original de la clase
Para quienes quieran revisar el código completo, he publicado la fuente en formato de texto. Lo rotulo como fuente original porque corresponde al código de la clase, aunque el archivo se haya subido como .txt para facilitar su publicación y descarga desde WordPress.
Descargar fuente original de la clase Fonetica
La idea central
La clase recibe un nombre escrito por una persona y lo transforma en una representación fonética numérica. Esa representación no pretende reemplazar el nombre original. Su función es ayudar al sistema a comparar nombres y encontrar posibles coincidencias.
En el comentario original de la clase aparece un ejemplo que resume muy bien la intención:
'Carlos Loria Beeche' --- '1962 69 42'Es decir:
Carlos → 1962
Loria → 69
Beeche → 42
El resultado final:
Carlos Loria Beeche → 1962 69 42Ese código no está hecho para que una persona lo lea como si fuera un nombre. Está hecho para que el sistema pueda buscar mejor.
Vista general de la clase
La imagen destacada de esta entrada muestra el diseño top-down de la clase. Vista desde arriba, la lógica es sencilla:
Nombre escrito
↓
codigoFonetico(nombre)
↓
fonemas(nombre)
↓
tokenAfonema(token)
↓
consonanteAFonema(char)
↓
Código fonético resultante
La clase separa el problema en pasos pequeños. Primero recibe el nombre completo. Luego lo divide en palabras. Después transforma cada palabra en una secuencia fonética. Finalmente une esos resultados para producir el código completo.
Una buena solución no siempre nace de una gran función complicada; muchas veces nace de dividir bien el problema.
Primera parte: estructura general y entrada
La primera parte de la clase contiene el namespace, la declaración de la clase, las tablas internas de equivalencia y los métodos principales de entrada.
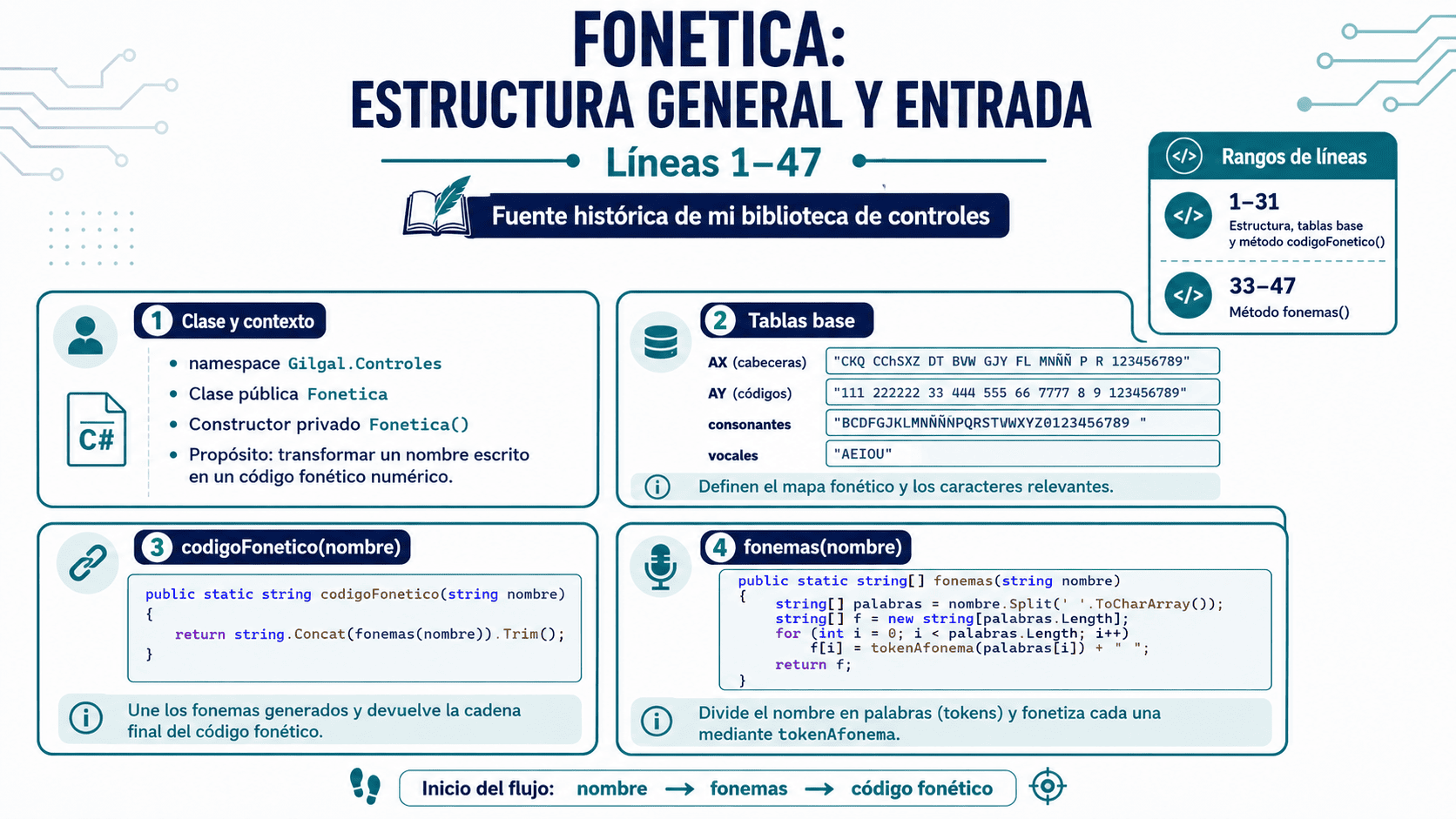
La clase utiliza varias cadenas internas que funcionan como tablas de conversión:
AX → letras o grupos de letras relevantes
AY → códigos fonéticos equivalentes
consonantes → caracteres considerados consonantes útiles
vocales → vocales usadas para reglas especiales
La idea es crear un mapa entre letras y grupos fonéticos. Por ejemplo, letras como C, K y Q pueden acercarse porque, en muchos nombres, pueden representar sonidos similares.
El método principal es:
codigoFonetico(nombre)Ese método llama a:
fonemas(nombre)Y fonemas(nombre) divide el nombre completo en palabras. Por ejemplo:
Carlos Loria Beeche
↓
Carlos
Loria
Beeche
Cada palabra se envía a tokenAfonema(token), donde se aplican las reglas fonéticas más importantes.
Segunda parte: tokenAfonema y las primeras reglas
El método tokenAfonema trabaja con una sola palabra, es decir, con un token sin espacios. Por ejemplo: Carlos, Loria o Beeche.
Primero convierte el token a mayúsculas y lo transforma en un arreglo de caracteres. Eso permite recorrer la palabra letra por letra y tomar decisiones según el contexto.
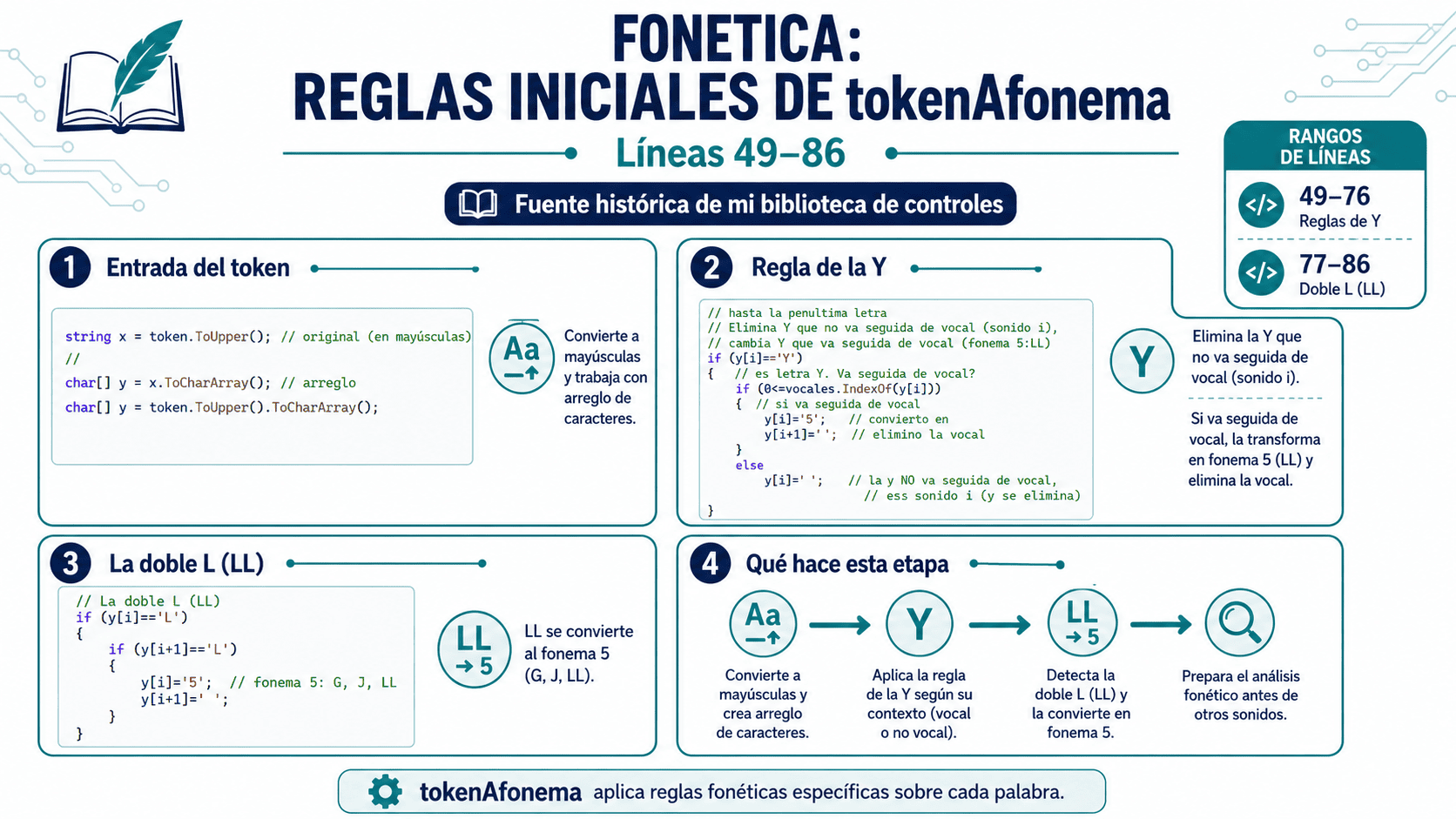
En esta etapa aparecen reglas propias de la fonética del español y de los nombres que se encontraban en recepción.
Por ejemplo, la doble LL se trata como un fonema especial:
LL → fonema 5Esto permite que la clase no vea simplemente dos letras L separadas, sino un sonido que puede tener identidad propia dentro del nombre.
También aparece la regla de la Y. La intención del comentario original es importante: la Y puede comportarse de forma distinta según su contexto. Puede sonar como vocal, o puede acercarse al sonido de LL cuando va seguida de vocal.
Este tipo de reglas muestran que la clase no se limita a eliminar caracteres. Intenta interpretar ciertos sonidos.
La búsqueda fonética no consiste solo en quitar letras; consiste en decidir qué diferencias importan para encontrar mejor.
Tercera parte: la letra C y las consonantes repetidas
Una de las reglas más interesantes está en el tratamiento de la letra C.
La C no siempre suena igual. Depende de la letra que viene después. Por eso la clase distingue varios casos.
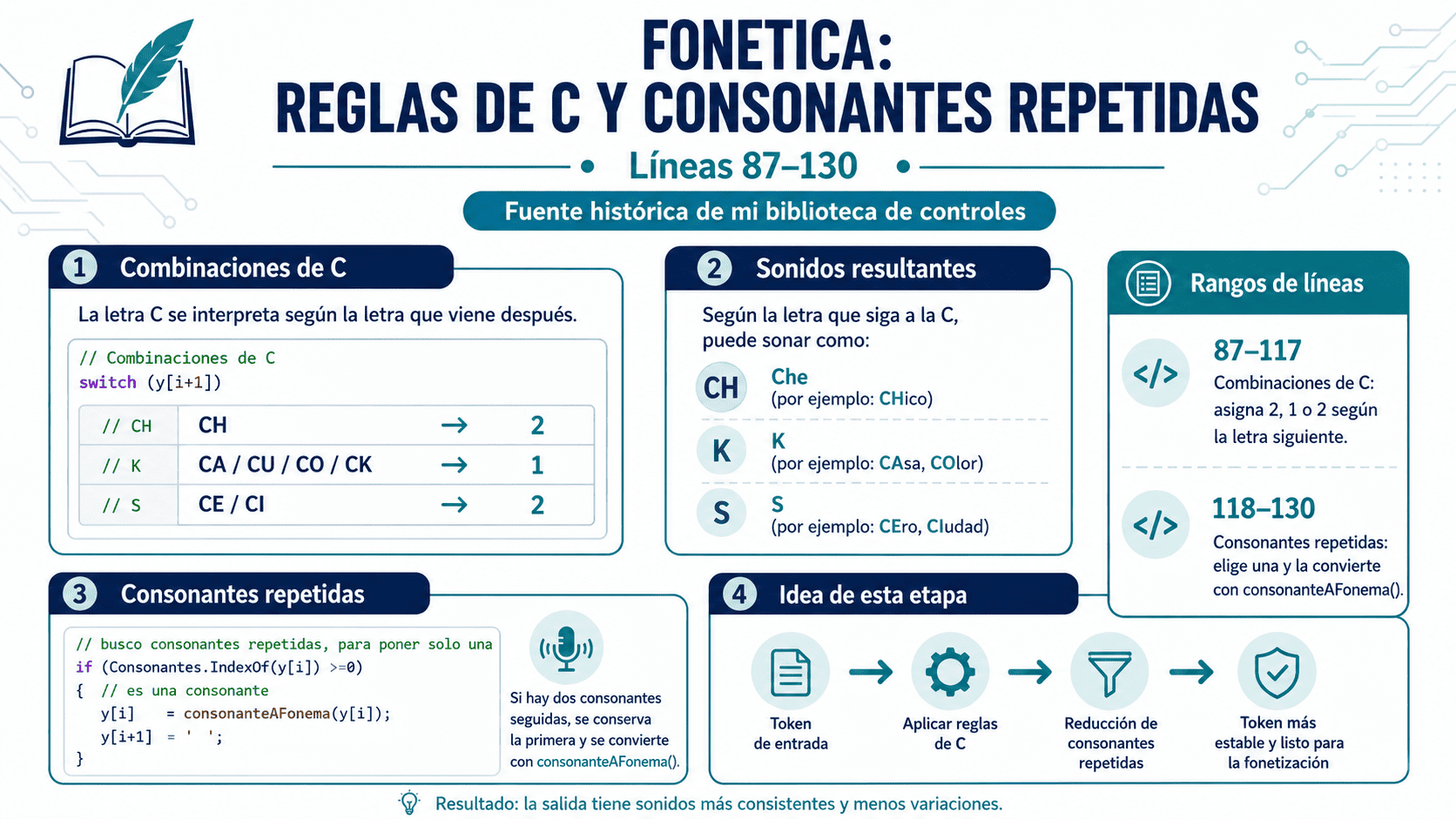
La lógica puede resumirse así:
CH → sonido CH
CA → sonido cercano a K
CO → sonido cercano a K
CU → sonido cercano a K
CK → sonido cercano a K
CE → sonido cercano a S
CI → sonido cercano a S
Esto tiene mucho sentido en una búsqueda fonética. Una C seguida de A, O o U no se comporta igual que una C seguida de E o I.
Por ejemplo:
Casa → C con sonido K
Coco → C con sonido K
César → C con sonido S
Ciro → C con sonido S
Chepe → CH como sonido propio
La clase también reduce consonantes repetidas. Si encuentra dos consonantes iguales seguidas, conserva una representación fonética y elimina la repetición.
Consonante repetida
↓
Se conserva una representación
↓
Se reduce ruido en la comparación
Esto ayuda a acercar nombres que pudieron haber sido escritos con letras duplicadas por error o por variación ortográfica.
Cuarta parte: limpieza final y mapeo de consonantes
Después de aplicar reglas especiales, la clase hace una limpieza final. Recorre la cadena, convierte consonantes pendientes a fonemas, elimina espacios en blanco innecesarios y compacta el resultado.
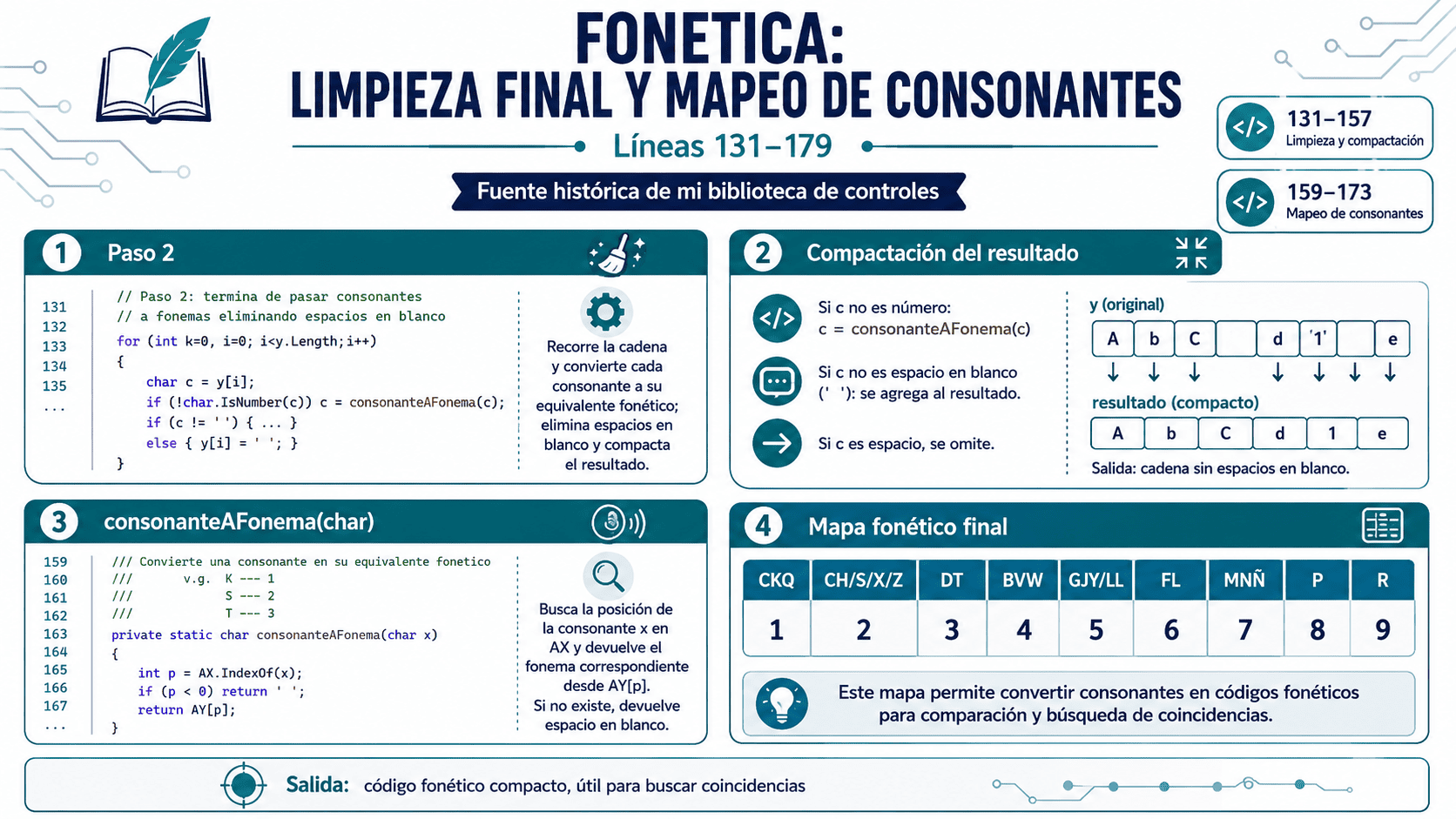
El método clave en esta etapa es:
consonanteAFonema(char x)Este método busca la consonante dentro de la tabla AX y devuelve el carácter equivalente desde AY.
En forma conceptual, el mapa fonético queda así:
CKQ → 1
CH/S/X/Z → 2
D/T → 3
B/V/W → 4
G/J/Y/LL → 5
F/L → 6
M/N/Ñ → 7
P → 8
R → 9
Si el carácter no aparece como consonante reconocida, la función devuelve un blanco. En la práctica, eso elimina vocales y caracteres especiales que no aportan al código fonético.
Construyendo el ejemplo: Carlos Loria Beeche
Ahora podemos entender el ejemplo original de la clase:
'Carlos Loria Beeche' --- '1962 69 42'Carlos → 1962
En Carlos, la C inicial se trata como sonido cercano a K porque va seguida de A. Luego se conservan sonidos relevantes como R, L y S. Las vocales desaparecen durante el proceso.
C A R L O S
↓ ↓ ↓ ↓
1 9 6 2
Carlos → 1962
Loria → 69
En Loria, las letras relevantes son principalmente L y R. Las vocales se eliminan.
L O R I A
↓ ↓
6 9
Loria → 69
Beeche → 42
En Beeche, la B se transforma en el grupo fonético 4. La combinación CH se transforma en el grupo fonético 2. Las vocales se eliminan.
B E E C H E
↓ ↓
4 2
Beeche → 42
Por eso el nombre completo termina convertido en:
Carlos Loria Beeche → 1962 69 42El resultado no reemplaza el nombre. Lo acompaña como una clave fonética para buscar coincidencias.
Por qué esta clase era útil
En un sistema de reservaciones, un huésped podía aparecer escrito de muchas maneras:
Carlos
Karlos
Karl
Carlo
C. Loria
Carlos Loría
Carlos Loria Beeche
Una búsqueda exacta podía fallar. Una búsqueda fonética podía acercar posibles coincidencias.
La clase Fonetica ayudaba a convertir nombres escritos de forma variable en códigos más comparables. Luego, combinada con la entidad Miembros, las raíces fonéticas y el motor de base de datos, el sistema podía presentar al usuario una lista de posibles perfiles relacionados.
La decisión final seguía siendo humana. El sistema no decía mágicamente “esta es la persona”. Lo que hacía era buscar mejor, reducir ruido y presentar mejores opciones.
La inteligencia no estaba en adivinar, sino en adaptarse mejor a la realidad de los nombres escritos por personas.
Una solución criolla, pero no improvisada
Esta clase resume bien lo que para mí significa una solución criolla bien entendida.
No era copiar un algoritmo internacional sin pensar. Tampoco era inventar desde cero ignorando lo que ya existía. Era estudiar ideas como Soundex, comprender el problema real, adaptar reglas al idioma y al negocio, y construir una herramienta útil para el sistema.
En ese sentido, la clase Fonetica no es solo una pieza de código. Es una pequeña muestra de cómo las estructuras de datos, las búsquedas fonéticas y la experiencia práctica pueden encontrarse en una solución concreta.
Cuando el software aprende a buscar de una forma más parecida a como las personas reconocen nombres, empieza a servir mejor.