Hay temas que uno no olvida, no porque fueran fáciles, sino porque marcaron una forma de pensar.
Cuando estudiaba Ciencias de la Computación, tuve como profesor a Adolfo Di Mare Hering, quien me enseñó estructuras de datos dentro de un curso de Lenguaje de Máquinas; es decir, en un curso de programación en lenguaje ensamblador, trabajando sobre la arquitectura de una IBM System/360 Model 40, aquella máquina que en la historia de la Universidad de Costa Rica aparece recordada como Cleotilde.
Años más tarde, el profesor Di Mare sería también mi director de tesis de Licenciatura. Por eso este recuerdo no es solo una anécdota de aula: es también una forma de gratitud hacia quien acompañó una parte importante de mi formación como estudiante, como programador y como profesional.
Durante mucho tiempo, en mi memoria afectiva, todo ese mundo universitario de computación antigua quedaba asociado con el nombre de Matilde, porque Matilde fue la computadora legendaria de la UCR, la primera gran referencia de aquellos años iniciales. Pero al revisar mejor la historia, conviene hacer la precisión: Matilde fue una IBM 1620; la IBM 360/40 fue Cleotilde. Y esa diferencia, lejos de quitarle encanto al recuerdo, lo ubica mejor en su verdadero lugar.
A primera vista, alguien podría preguntarse: ¿qué tienen que ver las estructuras de datos con el lenguaje ensamblador?
Con los años, la respuesta se vuelve más clara.
En un lenguaje tan cercano a la máquina, donde cada instrucción importa, donde los registros tienen nombre y propósito, donde la memoria no es una abstracción lejana sino un territorio concreto que se recorre dirección por dirección, uno aprende que programar no consiste solamente en escribir órdenes. Programar es organizar el pensamiento para que la máquina pueda ejecutarlo.
Y cuando pienso en aquel curso, hay una instrucción que nunca olvidé:
Branch and Link Register.
En particular, recuerdo aquella forma clásica de llamar una subrutina usando el registro 14 como lugar donde se guardaba la dirección de retorno. En términos sencillos: el programa saltaba a otra parte para ejecutar una rutina, pero antes debía dejar guardado el camino para poder regresar.
Ese detalle técnico me quedó grabado.
En términos sencillos, el programa cargaba en el registro 15 la dirección de la subrutina que quería ejecutar. Luego, con BALR 14,15, saltaba hacia esa subrutina, pero antes dejaba guardada en el registro 14 la dirección a la que debía regresar.
El regreso se hacía con una instrucción como BR 14. Allí estaba la elegancia del mecanismo: avanzar, ejecutar y volver. No perder el camino. No perder el contexto.
En la IBM System/360, el registro 14 guardaba el camino de regreso. Con los años comprendí que programar bien consiste precisamente en eso: saber avanzar sin perder la estructura que permite volver.
Porque allí, en una instrucción de bajo nivel, había una enseñanza profunda: avanzar no basta; hay que saber volver. Ejecutar no basta; hay que conservar el contexto. Resolver una parte del problema no basta; hay que mantener el orden de todo el programa.
Años después, al pensar en las estructuras de datos, entiendo mejor por qué nuestro profesor quería que aprendiéramos estas cosas en un curso de lenguaje ensamblador. No se trataba solamente de aprender arrays, listas, pilas o colas como conceptos aislados. Se trataba de aprender a pensar con disciplina, con estrategia, con respeto por la memoria.
Porque la memoria, cuando se organiza bien, deja de ser simplemente espacio disponible.
Se convierte en inteligencia.
Gracias, Adolfo.
El libro era Assembler Language for FORTRAN, COBOL, and PL/I Programmers, de Shan S. Kuo. El título mismo dice mucho de aquella época: no se trataba de aprender ensamblador como una curiosidad aislada, sino como un puente para entender lo que ocurría debajo de los lenguajes de alto nivel. Para quienes programaban en FORTRAN, COBOL o PL/I, el lenguaje ensamblador abría una ventana hacia la arquitectura real de la máquina: registros, direcciones, saltos, subrutinas, áreas de memoria y convenciones de llamada. Era una forma exigente, pero muy formativa, de descubrir que el software no flota en el aire; siempre descansa sobre una organización concreta de la memoria y del procesador.
La dedicatoria manuscrita de mi mamá, conservada todavía en las primeras páginas del libro. Mis padres me lo compraron con esfuerzo y cariño.
Hay objetos que guardan más que papel. Este libro, recomendado por el profesor Di Mare y comprado con esfuerzo por mis padres, conserva todavía una dedicatoria manuscrita de mi mamá. Al reencontrarlo tantos años después, comprendí que este post no debía ser solamente una explicación sobre estructuras de datos. También debía ser un acto de memoria y gratitud: hacia mis profesores, hacia mis padres, y hacia esa etapa en que aprender computación exigía paciencia, disciplina y mucha ilusión.
Antes de que la memoria de una computadora se convirtiera en inteligencia, hubo otra memoria más profunda: la memoria agradecida de quienes hicieron posible que uno estudiara.
¿Por qué hablar hoy de estructuras de datos?
Hoy vivimos rodeados de software. Usamos teléfonos, redes sociales, aplicaciones bancarias, sistemas de navegación, motores de búsqueda, plataformas de comercio electrónico, sistemas de facturación, bases de datos, inteligencia artificial y servicios que parecen responder de forma casi instantánea.
Pero debajo de esa aparente magia hay decisiones muy concretas. Decisiones sobre cómo guardar, buscar, ordenar, recorrer, modificar y relacionar datos.
Una estructura de datos es, dicho de manera sencilla, una forma organizada de guardar información. Pero esa definición se queda corta. En realidad, una estructura de datos es una decisión de diseño. Es una manera de decirle a la computadora: “esto lo vamos a ordenar así porque luego necesitaremos usarlo de cierta forma”.
Un programador principiante puede pensar que lo importante es simplemente “hacer que funcione”. Pero con el tiempo uno descubre otra dimensión: no basta con que funcione; importa también cómo funciona, cuánto tarda, cuánta memoria consume, qué tan fácil será mantenerlo y qué tan bien responderá cuando crezca la cantidad de información.
Por eso las estructuras de datos siguen siendo fundamentales. No pertenecen únicamente a un lenguaje de programación. Se pueden estudiar en C, C++, Java, C#, Python, JavaScript o cualquier otro lenguaje moderno. Cambia la sintaxis, cambian las bibliotecas, cambian las comodidades del programador; pero la idea profunda permanece.
Las estructuras de datos son parte del arte silencioso detrás del software moderno.
En aquellos años también aparecía, como referencia casi inevitable, el nombre de Donald E. Knuth. Su obra The Art of Computer Programming tenía —y sigue teniendo— ese carácter de libro mayor: exigente, profundo, a veces intimidante, pero lleno de una idea fundamental. La programación no es solamente una técnica para producir resultados; es también un arte de precisión. Knuth nos enseñaba que detrás de un algoritmo hay belleza, orden, análisis y responsabilidad intelectual. Por eso, hablar de estructuras de datos es también volver a esa tradición en la que programar significaba pensar cuidadosamente antes de escribir una sola línea de código.
Las ocho estructuras que vamos a recorrer
En esta primera entrega no pretendo agotar el tema. Más bien quiero abrir la puerta. Pero sí conviene presentar el mapa general de la saga, porque estas estructuras no son adornos académicos: son herramientas fundamentales para pensar correctamente el software.
El orden no es casual. Empezamos con estructuras más sencillas y visibles, y poco a poco avanzamos hacia estructuras más poderosas, capaces de representar relaciones complejas, prioridades, jerarquías y caminos.
1. Array: el estacionamiento numerado de la memoria
Un array, o arreglo, es una de las estructuras más básicas y más importantes. Se puede imaginar como un estacionamiento de un centro comercial: cada espacio tiene un número, y si conocemos ese número podemos ir directamente al lugar que necesitamos.
En términos técnicos, un array guarda elementos en posiciones consecutivas de memoria. Cada elemento se accede mediante un índice. Por eso, si tenemos un arreglo de nombres, números, productos o registros, podemos pedir directamente el elemento que está en la posición 0, 1, 2, 3, y así sucesivamente.
La gran ventaja del array es el acceso directo. Si sé que necesito el elemento número 50, no tengo que revisar los 49 anteriores. Voy directamente a esa posición.
Pero esa eficiencia tiene un costo. Si quiero insertar un elemento en medio del arreglo, muchas veces debo mover otros elementos para abrir espacio. Si quiero eliminar uno, también puede ser necesario reacomodar los demás. Por eso el array es excelente cuando queremos acceso rápido por posición, pero no siempre es la mejor opción cuando necesitamos insertar y borrar constantemente en medio de la colección.
En la vida real, los arrays aparecen por todas partes: listas de precios, colecciones de valores, resultados ordenados, vectores, matrices, tablas, buffers y muchas estructuras internas de los lenguajes de programación.
El array nos enseña una primera lección: cuando la información está bien numerada y ordenada, llegar a ella puede ser casi instantáneo.
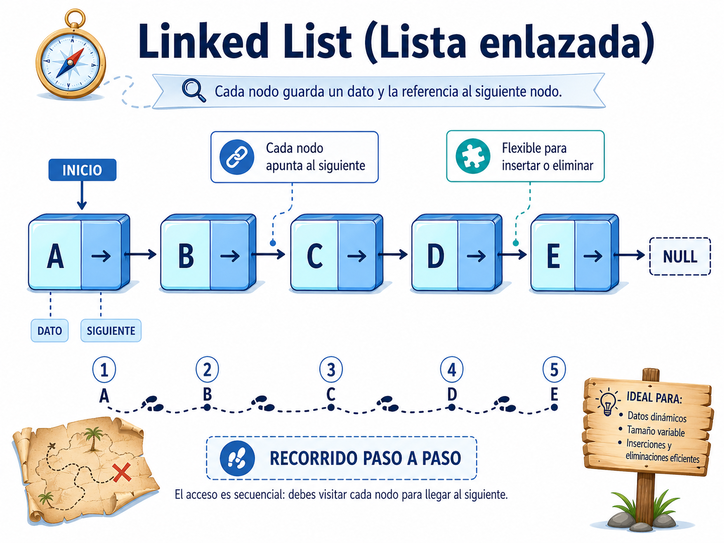
2. Linked List: la búsqueda del tesoro
Una linked list, o lista enlazada, funciona de una manera muy distinta. En lugar de guardar todo como una fila compacta y numerada, cada elemento guarda su propio valor y además una referencia al siguiente elemento.
Por eso se puede comparar con una búsqueda del tesoro. Uno encuentra una pista, y esa pista le dice dónde está la siguiente. Luego la siguiente lleva a otra, y así sucesivamente.
Cada elemento de una lista enlazada suele llamarse nodo. Un nodo contiene dos cosas: el dato que queremos guardar y una referencia hacia el próximo nodo. En algunas listas, llamadas doblemente enlazadas, cada nodo también puede guardar una referencia al nodo anterior.
La ventaja de una lista enlazada es que insertar o eliminar elementos puede ser más flexible que en un array, especialmente cuando ya sabemos dónde queremos hacer el cambio. No siempre hay que mover toda una colección de datos. Basta con ajustar referencias.
Pero también hay un costo: no podemos ir directamente al elemento número 50 como en un array. Para llegar allí, normalmente debemos empezar desde el primer nodo y avanzar uno por uno hasta encontrarlo. Es decir, la lista enlazada es buena para reorganizar, pero no tan buena para acceso directo por posición.
Esta diferencia es fundamental. En programación, muchas decisiones consisten precisamente en escoger qué operación será más frecuente: buscar por posición, insertar, eliminar, recorrer, ordenar o reorganizar.
La lista enlazada nos recuerda que no toda información necesita estar en una fila compacta; a veces basta con saber cuál es el siguiente paso.
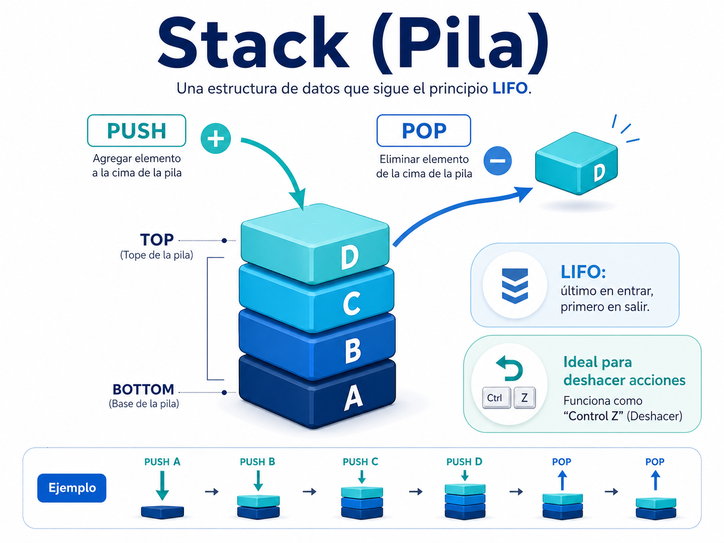
3. Stack: la pila y el recuerdo del último paso
Una stack, o pila, trabaja con una regla muy sencilla: el último elemento en entrar es el primero en salir. En inglés se le llama LIFO: Last In, First Out.
La analogía clásica es una pila de platos. Si colocamos un plato encima de otro, el primero que podemos quitar es el último que pusimos. No sacamos el plato de abajo sin mover los de arriba.
En el software, una pila aparece en muchas situaciones. Un ejemplo cotidiano es el famoso Control Z. Cuando deshacemos acciones en un editor de texto, normalmente se deshace primero la última acción realizada. Luego la anterior. Luego la anterior. Es una pila de acciones.
También aparece en la ejecución de programas. Cuando una función llama a otra función, y esa otra llama a otra más, el programa necesita recordar por dónde debe regresar. Allí aparece la idea de una pila de llamadas. Se van apilando contextos, direcciones de retorno, variables locales y estados temporales.
Por eso, al recordar el registro 14 y la instrucción BALR 14,15 en la IBM System/360, la conexión con las estructuras de datos se vuelve más clara. El programa no solo saltaba a una subrutina; necesitaba conservar la información necesaria para volver. Esa necesidad de guardar contexto está muy cerca del corazón conceptual de una pila.
Las operaciones básicas de una pila suelen llamarse push y pop. Con push agregamos un elemento arriba de la pila. Con pop quitamos el elemento superior. También puede existir una operación para mirar el elemento superior sin quitarlo, a veces llamada peek.
La pila nos enseña que el orden de regreso importa: a veces, para avanzar correctamente, primero hay que resolver lo último que quedó pendiente.
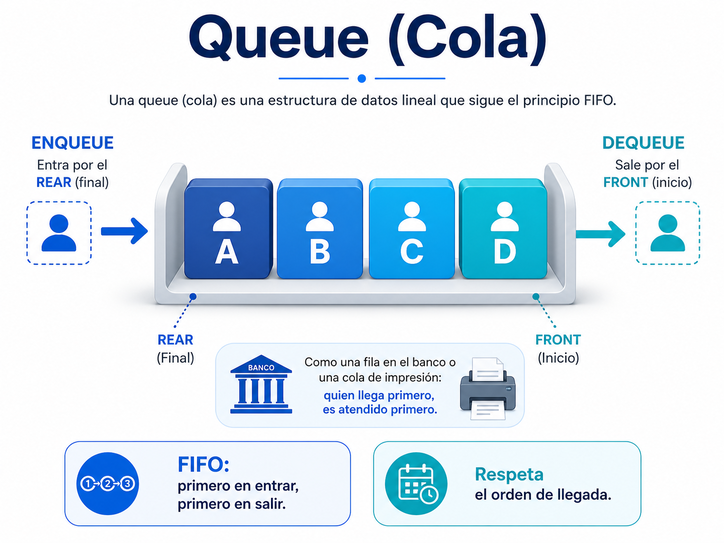
4. Queue: la cola y la justicia del turno
Una queue, o cola, funciona con la regla contraria a la pila. Aquí, el primero en entrar es el primero en salir. En inglés se le llama FIFO: First In, First Out.
La analogía más sencilla es una fila de banco. Quien llega primero debe ser atendido primero. También podemos pensar en una cola de impresión: los documentos se imprimen en el orden en que fueron enviados, salvo que exista alguna prioridad especial.
Las colas son esenciales en sistemas donde el orden de llegada importa. Por ejemplo, procesamiento de tareas, mensajes pendientes, solicitudes a un servidor, trabajos de impresión, atención de eventos, comunicaciones entre procesos y sistemas que reciben muchas peticiones al mismo tiempo.
Las operaciones básicas suelen llamarse enqueue y dequeue. Con enqueue agregamos un elemento al final de la cola. Con dequeue sacamos el elemento del frente.
Una cola enseña una idea muy importante: no todo se resuelve por urgencia inmediata ni por último movimiento. A veces la regla correcta es respetar el orden de llegada. El software moderno usa colas constantemente para ordenar trabajo, evitar saturación y procesar tareas de forma controlada.
La cola nos recuerda que también en el software hay turnos, esperas y procesos que deben avanzar con orden.
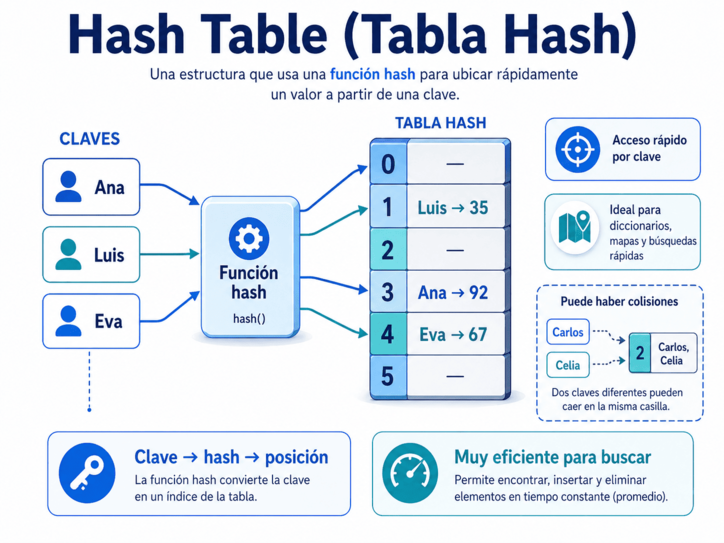
5. Hash Table: encontrar sin buscar
Una hash table, o tabla hash, es una estructura de datos diseñada para encontrar información con gran rapidez a partir de una clave.
La idea central es muy poderosa: una función matemática, llamada función hash, toma una clave y la convierte en una posición dentro de una tabla. En lugar de revisar elemento por elemento, el programa calcula dónde debería estar el dato y va directamente a esa ubicación.
Podemos imaginarla como un diccionario muy eficiente. Si queremos buscar una palabra, no empezamos desde la primera página y avanzamos una por una. Usamos algún criterio para ir directamente a la sección correcta. En una tabla hash ocurre algo parecido, pero con una función que transforma claves en posiciones.
Las tablas hash aparecen en muchos lugares: diccionarios, mapas, objetos, índices, sistemas de búsqueda, cachés, conteos de frecuencia y estructuras internas de muchos lenguajes modernos.
Su gran ventaja es la velocidad promedio de acceso. Buscar, insertar o eliminar un elemento puede ser muy rápido cuando la función hash está bien diseñada y la tabla tiene suficiente espacio.
Pero también existe un detalle importante: las colisiones. Una colisión ocurre cuando dos claves distintas terminan apuntando a la misma posición. Por eso las tablas hash necesitan estrategias para resolver esos casos, como guardar varios elementos en una misma casilla o buscar otra posición disponible.
La tabla hash nos enseña que, cuando existe una buena clave y una buena función para interpretarla, buscar puede dejar de ser un recorrido y convertirse casi en un salto directo.
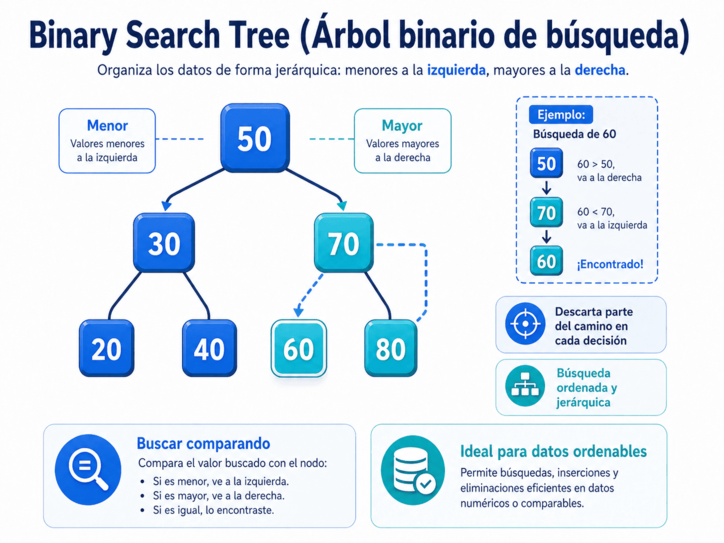
6. Binary Search Tree: ordenar para encontrar mejor
Un binary search tree, o árbol binario de búsqueda, organiza la información de forma jerárquica.
Cada elemento se guarda en un nodo. Cada nodo puede tener, como máximo, dos hijos: uno a la izquierda y otro a la derecha. La regla fundamental es sencilla: los valores menores se colocan hacia la izquierda, y los valores mayores hacia la derecha.
Gracias a esa regla, la búsqueda se vuelve más inteligente. Si estamos buscando un valor y comparamos con el nodo actual, podemos decidir hacia dónde continuar. Si el valor buscado es menor, vamos a la izquierda. Si es mayor, vamos a la derecha. Si es igual, lo encontramos.
La belleza de esta estructura está en que cada comparación puede descartar una parte importante del camino. En lugar de revisar todos los elementos uno por uno, el árbol permite tomar decisiones sucesivas que reducen el espacio de búsqueda.
Un árbol binario de búsqueda puede usarse para mantener datos ordenados, facilitar búsquedas, insertar nuevos valores y eliminar elementos conservando cierta organización. Sin embargo, su eficiencia depende de que el árbol no quede demasiado desbalanceado. Si todos los elementos se insertan en orden, el árbol puede degenerar y parecerse más a una lista que a un árbol eficiente.
Por eso, en aplicaciones más avanzadas, existen variantes de árboles balanceados que buscan conservar una forma más equilibrada.
El árbol binario de búsqueda nos recuerda que el orden no solo sirve para presentar mejor la información; también puede hacer que encontrarla sea mucho más rápido.
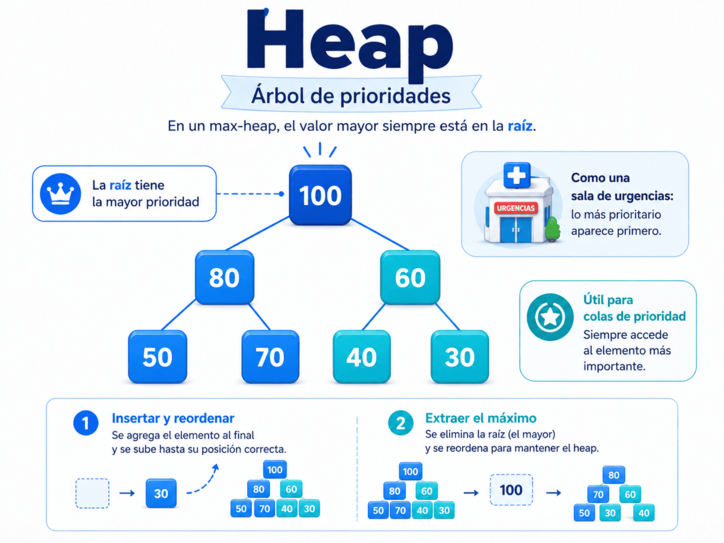
7. Heap: cuando la prioridad manda
Un heap es una estructura de datos basada en prioridades. Aunque se representa como un árbol, no pretende mantener todos los elementos completamente ordenados. Su objetivo principal es asegurar que el elemento más importante esté siempre disponible en la parte superior.
En un max-heap, el valor mayor se mantiene en la raíz. En un min-heap, el valor menor ocupa ese lugar. Lo importante es que la raíz siempre representa el elemento de mayor prioridad según la regla definida.
Una buena analogía es una sala de urgencias. No siempre se atiende primero a quien llegó primero, sino a quien necesita atención más inmediata. En ese caso, la prioridad manda sobre el simple orden de llegada.
Los heaps son muy útiles para implementar colas de prioridad. También aparecen en algoritmos de ordenamiento, planificación de tareas, sistemas de eventos, simulaciones, rutas y muchos problemas donde necesitamos extraer repetidamente el elemento más importante.
La operación típica consiste en insertar un nuevo elemento y reacomodarlo hasta que ocupe su lugar correcto, o extraer la raíz y reorganizar el árbol para que vuelva a cumplirse la propiedad del heap.
Así, el heap no se preocupa por ordenar absolutamente todo. Se concentra en una pregunta más práctica: ¿cuál es el elemento que debe salir primero según su prioridad?
El heap nos enseña que no siempre importa tener todo perfectamente ordenado; a veces basta con saber cuál es lo más urgente, lo más grande, lo más pequeño o lo más importante.
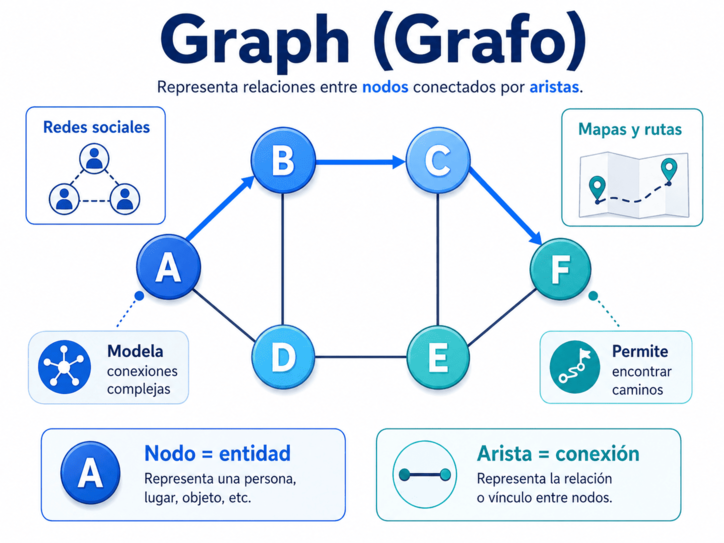
8. Graph: cuando los datos forman caminos
Un graph, o grafo, es una de las estructuras de datos más poderosas, porque permite representar relaciones complejas entre elementos.
Un grafo está formado por nodos y aristas. Los nodos representan entidades: personas, ciudades, páginas web, computadoras, tareas, objetos o cualquier elemento que queramos modelar. Las aristas representan conexiones, vínculos o relaciones entre esos nodos.
Gracias a los grafos podemos representar problemas del mundo real donde lo importante no es solamente guardar datos, sino entender cómo se conectan entre sí.
Una red social puede verse como un grafo: cada persona es un nodo y cada amistad, seguimiento o relación es una arista. Un mapa de carreteras también puede verse como un grafo: cada ciudad o punto de interés es un nodo, y cada carretera o ruta es una conexión. Internet, los sistemas de recomendación, las dependencias entre proyectos y las rutas de navegación también pueden modelarse con grafos.
Los grafos permiten responder preguntas muy interesantes: ¿existe un camino entre dos puntos? ¿Cuál es la ruta más corta? ¿Qué nodos están más conectados? ¿Dónde hay comunidades? ¿Qué dependencias deben resolverse antes que otras?
Por eso los grafos son fundamentales en navegación, redes sociales, buscadores, inteligencia artificial, análisis de redes, logística, compiladores, bases de datos y muchísimos otros campos.
El grafo nos enseña que muchos problemas no consisten en ordenar una lista, sino en descubrir relaciones, caminos y conexiones.
Lo que vendrá en los próximos artículos
En esta primera entrega he querido presentar una visión general de las ocho estructuras de datos fundamentales. La intención es que podamos ver el mapa completo antes de entrar en los detalles de cada camino.
Pero esta saga no se quedará solamente en la explicación conceptual. En los próximos artículos iremos estructura por estructura, con más calma, entrando ya en ejemplos concretos de programación.
Cuando estudiemos cada estructura, veremos cómo se representa, cuáles son sus operaciones básicas, qué ventajas ofrece, cuáles son sus limitaciones y en qué situaciones conviene usarla. También incluiremos ejemplos de código en lenguajes conocidos, como C++, C# y Python, para pasar de la idea general a la implementación práctica.
Así, este primer artículo funciona como una puerta de entrada. Las siguientes entregas serán más técnicas y específicas: veremos cómo crear un array, cómo recorrer una lista enlazada, cómo usar una pila, cómo procesar una cola, cómo implementar una tabla hash, cómo buscar en un árbol, cómo trabajar con heaps y cómo modelar relaciones mediante grafos.
La idea es avanzar paso a paso: primero entender la intuición, luego ver la estructura, y finalmente programarla.
Una pequeña saga
Podríamos decir, con una sonrisa, que esta será una pequeña saga. Como en La guerra de las galaxias, habrá secuelas: no porque queramos complicar la historia, sino porque cada estructura merece su propio momento, su propio escenario y su propia batalla.
Algunas estructuras nos enseñan a ordenar. Otras nos enseñan a esperar. Otras nos enseñan a buscar rápido. Otras nos enseñan a dar prioridad. Y otras nos permiten descubrir caminos entre elementos que, a simple vista, parecían separados.
Mi intención no es escribir solamente para especialistas. Quisiera que estos textos también puedan leerlos familiares, amigos y personas curiosas que tal vez no programan todos los días, pero que sí viven rodeadas de software. Porque entender un poco cómo se organiza la información es también entender mejor el mundo digital en el que vivimos.
Esta será una pequeña saga sobre memoria, orden e inteligencia: una invitación a descubrir el arte silencioso detrás del software moderno.
De la memoria al pensamiento
Cuando vuelvo mentalmente a aquella IBM System/360 Model 40, a Cleotilde, al lenguaje ensamblador, al registro 14, a la instrucción BALR 14,15, al libro recomendado por mi profesor y a la dedicatoria de mi mamá, comprendo que las estructuras de datos no son solamente una materia universitaria.
Son una forma de educación del pensamiento.
Nos enseñan que no todo puede guardarse de cualquier manera. Nos enseñan que el orden importa. Nos enseñan que cada decisión tiene consecuencias. Nos enseñan que la eficiencia no aparece por accidente, sino por diseño.
Y quizá esa sea una lección que va más allá de la computación.
Porque también en la vida necesitamos estructuras: memoria para no olvidar, orden para no perdernos, prioridades para atender lo importante, caminos para avanzar y humildad para reconocer a quienes nos ayudaron a llegar hasta aquí.
Por eso inicio esta serie con gratitud.
Gratitud hacia mi profesor Adolfo Di Mare Hering, por haberme enseñado que detrás de cada instrucción puede esconderse una manera de pensar.
Gratitud hacia mis padres, por aquel libro comprado con esfuerzo.
Gratitud hacia mi mamá, por aquella dedicatoria que todavía conserva su letra, su cariño y su fe en mi camino.
Y gratitud también por la posibilidad de volver, tantos años después, sobre estos temas que siguen vivos.
Porque programar bien no es solamente dar órdenes a una máquina.
Es aprender a pensar con claridad, con estrategia y con respeto por la memoria.
Sugerencias para seguir la serie
En esta primera entrega hemos abierto el mapa general de las ocho estructuras de datos fundamentales. En los próximos artículos iremos una por una, con más detalle técnico, ejemplos de programación y aplicaciones prácticas.
En esas entregas entraremos ya en ejemplos concretos de programación, usando lenguajes como C++, C# y Python, para pasar de la intuición a la implementación.


 Lic. Carlos Enrique Loria Beeche.
Lic. Carlos Enrique Loria Beeche.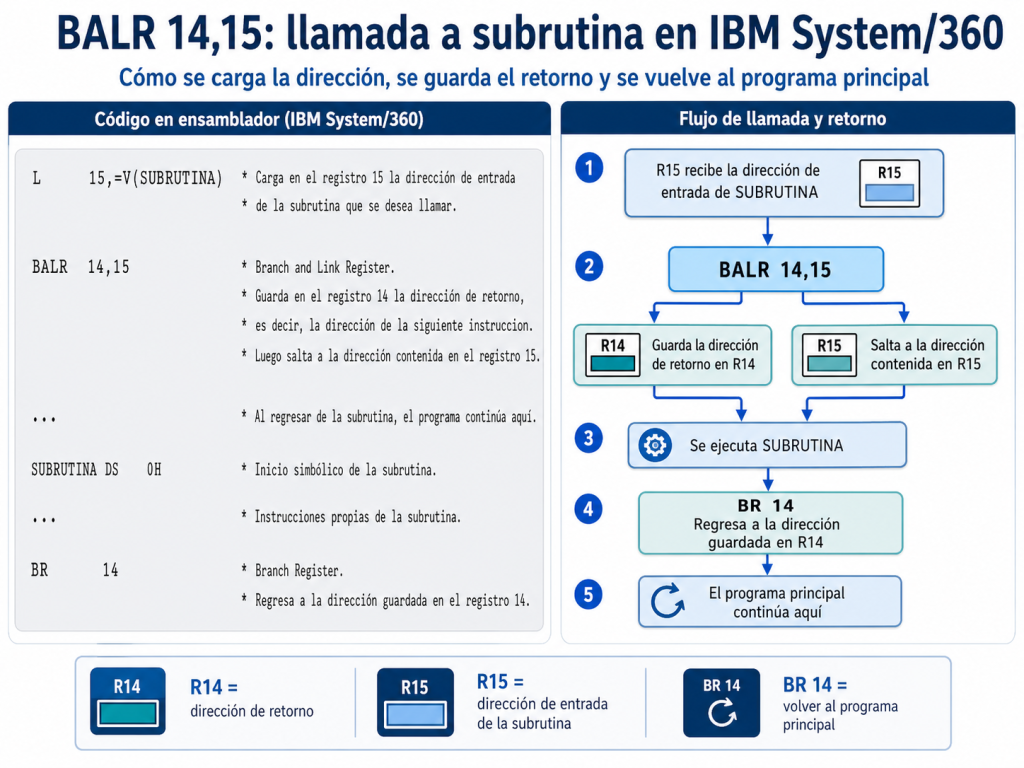

 El libro era Assembler Language for FORTRAN, COBOL, and PL/I Programmers, de Shan S. Kuo. El título mismo dice mucho de aquella época: no se trataba de aprender ensamblador como una curiosidad aislada, sino como un puente para entender lo que ocurría debajo de los lenguajes de alto nivel. Para quienes programaban en FORTRAN, COBOL o PL/I, el lenguaje ensamblador abría una ventana hacia la arquitectura real de la máquina: registros, direcciones, saltos, subrutinas, áreas de memoria y convenciones de llamada. Era una forma exigente, pero muy formativa, de descubrir que el software no flota en el aire; siempre descansa sobre una organización concreta de la memoria y del procesador.
El libro era Assembler Language for FORTRAN, COBOL, and PL/I Programmers, de Shan S. Kuo. El título mismo dice mucho de aquella época: no se trataba de aprender ensamblador como una curiosidad aislada, sino como un puente para entender lo que ocurría debajo de los lenguajes de alto nivel. Para quienes programaban en FORTRAN, COBOL o PL/I, el lenguaje ensamblador abría una ventana hacia la arquitectura real de la máquina: registros, direcciones, saltos, subrutinas, áreas de memoria y convenciones de llamada. Era una forma exigente, pero muy formativa, de descubrir que el software no flota en el aire; siempre descansa sobre una organización concreta de la memoria y del procesador.